The Great Reversal
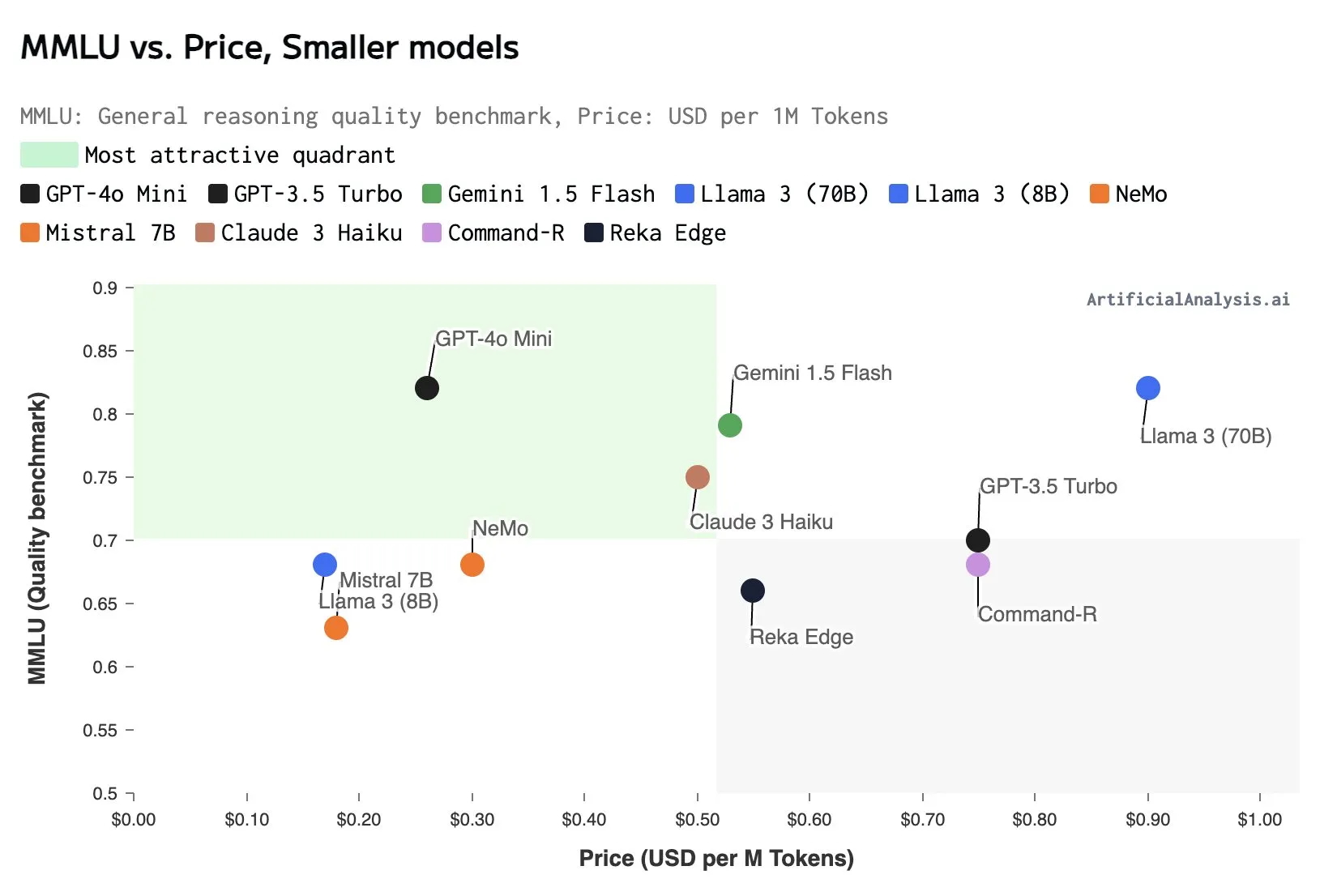
Something interesting is happening in AI. After years of “bigger is better,” we’re seeing a shift towards smaller, more efficient models. Mistral just released NeMo and OpenAI unveiled GPT40-mini. Google’s in on it too, with Gemini Flash. What’s going on?
It’s simple: we’ve hit diminishing returns with giant models.
Training massive AI models is expensive. Really expensive. We’re talking millions of dollars and enough energy to power a small town. For a while, this seemed worth it. Bigger models meant better performance, and tech giants were happy to foot the bill in the AI arms race.
But here’s the thing: throwing more parameters at the problem only gets you so far. It turns out that data quality matters way more than sheer model size. And high-quality data? That’s getting scarce.