The Great Reversal¶
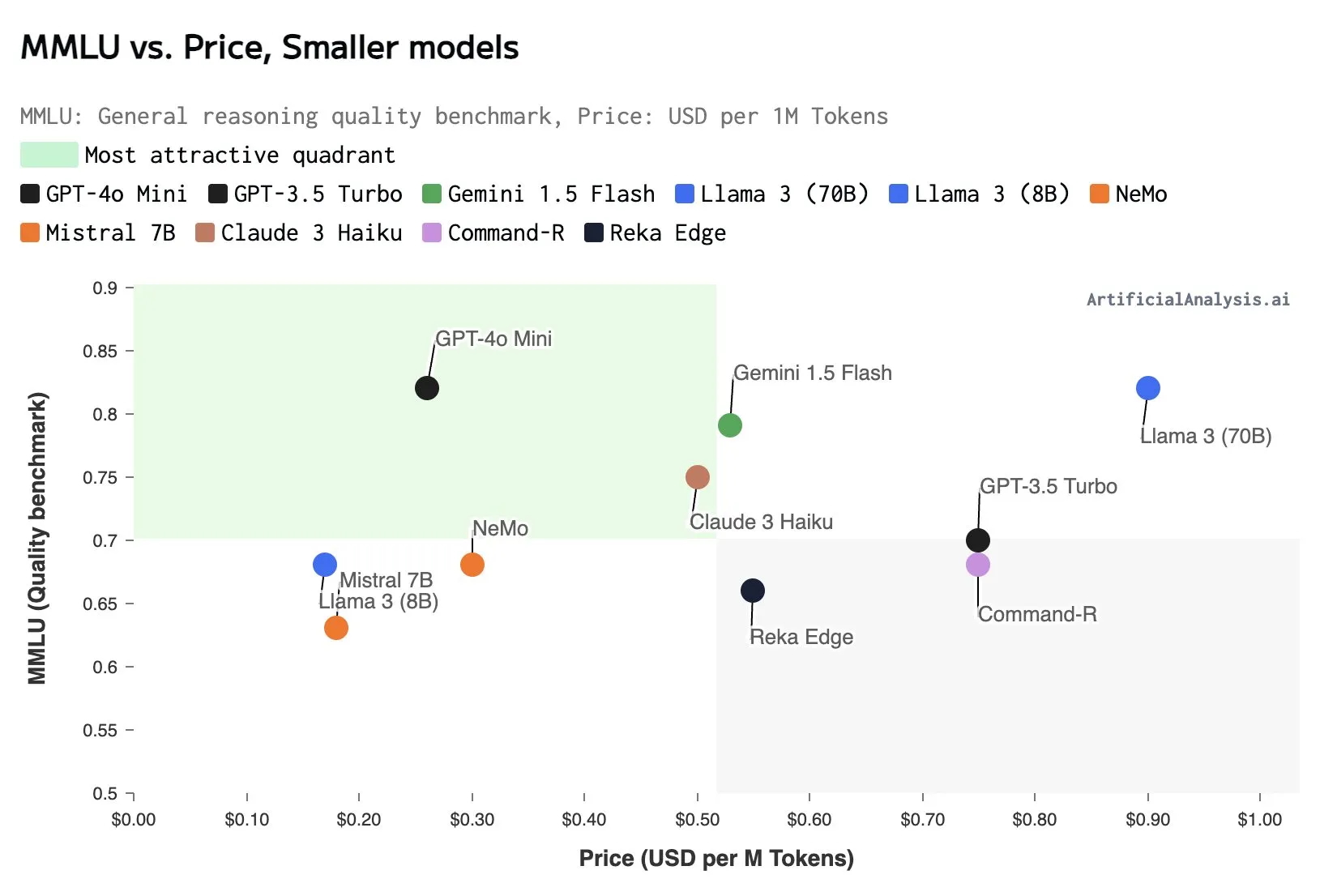
Something interesting is happening in AI. After years of “bigger is better,” we’re seeing a shift towards smaller, more efficient models. Mistral just released NeMo and OpenAI unveiled GPT40-mini. Google’s in on it too, with Gemini Flash. What’s going on?
It’s simple: we’ve hit diminishing returns with giant models.
Training massive AI models is expensive. Really expensive. We’re talking millions of dollars and enough energy to power a small town. For a while, this seemed worth it. Bigger models meant better performance, and tech giants were happy to foot the bill in the AI arms race.
But here’s the thing: throwing more parameters at the problem only gets you so far. It turns out that data quality matters way more than sheer model size. And high-quality data? That’s getting scarce.
The AI hype cycle is cooling off, too. Investors aren’t as eager to pour endless cash into projects with unclear paths to profitability. Companies are feeling the pressure to actually make money from their AI investments.
So, we’re seeing a pivot. Smaller, more focused models are having their moment. And a funny thing happened: in many cases, these “mini” models are outperforming their massive counterparts. How? By being called multiple times in clever ways, rather than relying on a single, monolithic prediction.
This shift is more important than it might seem at first glance.
For one, it lowers the barrier to entry. When you need a supercomputer and millions of dollars just to play the game, innovation stagnates. Only a handful of companies can compete. But with smaller models, suddenly university labs and startups can join in. New ideas can be tested without breaking the bank.
It also changes the nature of the competition. Instead of a brute-force race to build bigger models, we’re seeing a renewed focus on algorithmic improvements. It’s not about who has the most compute anymore; it’s about who can squeeze the most performance out of limited resources.
This is great news for machine learning research. Think about it: when the standard is a model that takes months to train and costs millions to run, how can academics meaningfully contribute? How can we test truly novel architectures if scaling them up to “competitive” size is impossible for most labs?
But if the playing field levels out, suddenly we can measure progress more easily. We can iterate faster. We might even see breakthroughs that challenge the dominance of transformer architectures.
There’s an environmental angle, too. AI’s energy consumption has been skyrocketing. A shift towards efficiency isn’t just good business—it’s necessary for sustainability.
Don’t get me wrong: large language models aren’t going away. They’ll still have their place. But this trend towards “small and smart” over “big and brute force” feels like a natural evolution of the field.
It reminds me of the transition from mainframes to personal computers. At first, the idea that a small machine on your desk could rival the power of a room-sized computer seemed absurd. But as hardware improved and software became more efficient, PCs not only caught up but opened up entirely new possibilities. They democratized computing, leading to an explosion of innovation.
We might be seeing a similar inflection point in AI. The winners of the next phase won’t necessarily be the ones with the biggest models, but the ones who can do the most with the least.
It’s an exciting time. The AI field is maturing, moving from raw growth to refined efficiency. And in that shift, we might just see the next big leap forward.